Search¶
To search for documents indexed in Nixiesearch, you can use the following request JSON format:
{
"query": {
"multi_match": {
"fields": ["<search-field-name>", "<search-field-name>"],
"query": "<query-string>"
}
}
}
Where:
<search-field-name>: a text field marked as searchable in the index mapping<query-string>: a string to search for.multi_match: one of the matching DSL rules. Check more examples of Query DSL in the reference.
For such a search request, Nixiesearch will reply with a JSON response with top-N matching documents:
{
"took": 100,
"hits": [
{"_id": "1", "title": "hello", "_score": 2},
{"_id": "2", "title": "world", "_score": 1}
]
}
_id and _score are built-in fields always present in the document payload.
Note
Compared to Elasticsearch/Opensearch, Nixiesearch has no built-in _source field as it is frequently mis-used. You need to explicitly mark fields you want to be present in response payload as store: true in the index mapping.
RAG: Retrieval Augmented Generation¶
Instead of just getting search results for your query, you can use a RAG approach to get a natural language answer to your query, built with locally-running LLM.
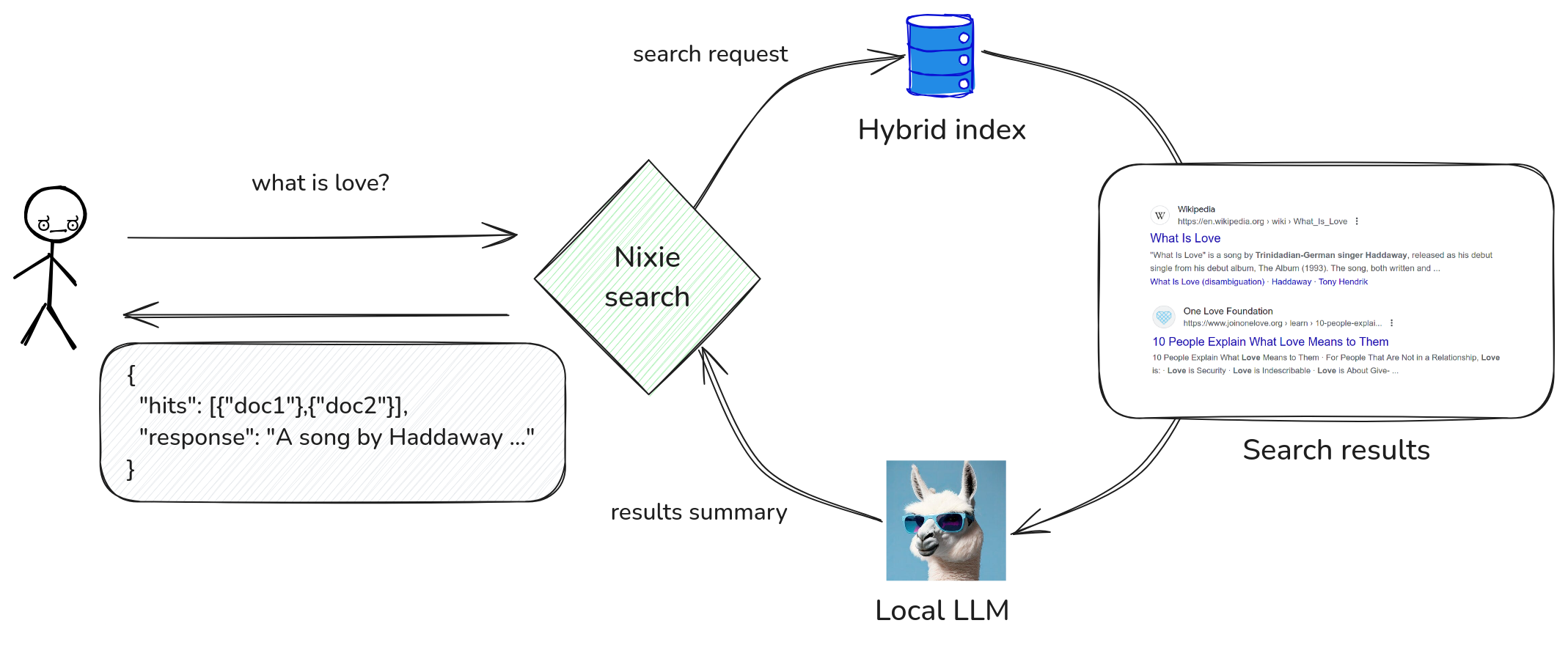
Nixiesearch supports any GGUF-compatible LLM llamacpp supports. To use RAG, you need to list Huggingface handles of models you'd like to use in the inference section of the config file:
inference:
embedding:
# Used for semantic retrieval
e5-small:
model: nixiesearch/e5-small-v2-onnx
prompt:
doc: "passage: "
query: "query: "
completion:
# Used for summarization
qwen2:
provider: llamacpp
model: Qwen/Qwen2-0.5B-Instruct-GGUF
file: qwen2-0_5b-instruct-q4_0.gguf
prompt: qwen2
schema:
movies:
fields:
title:
type: text
search:
type: semantic
model: e5-small
suggest: true
overview:
type: text
search:
type: semantic
model: e5-small
suggest: true
Here we use a Qwen/Qwen2-0.5B-Instruct-GGUF model with explicitly defined filename (as there may be multiple GGUF model files in the repo).
LLM inference on a CPU is a tough task, expect much higher latencies for RAG requests, compared to regular ones.
After that we can send RAG search requests to our index:
{
"query": {
"multi_match": {
"fields": ["title", "description"],
"query": "what is pizza"
}
},
"rag": {
"prompt": "Summarize search results for a query 'what is pizza'",
"model": "qwen2",
"fields": ["title", "description"]
}
}
For this query, Nixiesearch will perform following actions:
* Make a search for the query what is pizza over title and description fields
* pick top-N matching documents from results, and build an LLM prompt:
Summarize search results for a query 'what is pizza':
[1]: Pizza is a traditional Italian dish typically consisting of ...
[2]: One of the simplest and most traditional pizzas is the Margherita ...
[3]: The meaning of PIZZA is a dish made typically of flattened bread dough ...
{
"took": 10,
"hits": [
{"_id": 1, "title": "...", "description": "..."},
{"_id": 1, "title": "...", "description": "..."},
{"_id": 1, "title": "...", "description": "..."}
],
"response": "Pizza is a dish of Italian origin ..."
}
As LLM inference is a costly operation, Nixiesearch supports a WebSocket response streaming: you immediately get search result documents in a first frame, and LLM-generated tokens are streamed while being generated. See RAG reference for more details.
Hybrid search with Reciprocal Rank Fusion¶
When you search over multiple fields marked a hybrid field, Nixiesearch does the following:
- Collects a separate per-field search result list for semantic and lexical retrieval methods.
- Merges N search results with RRF - Reciprocal Rank Fusion.
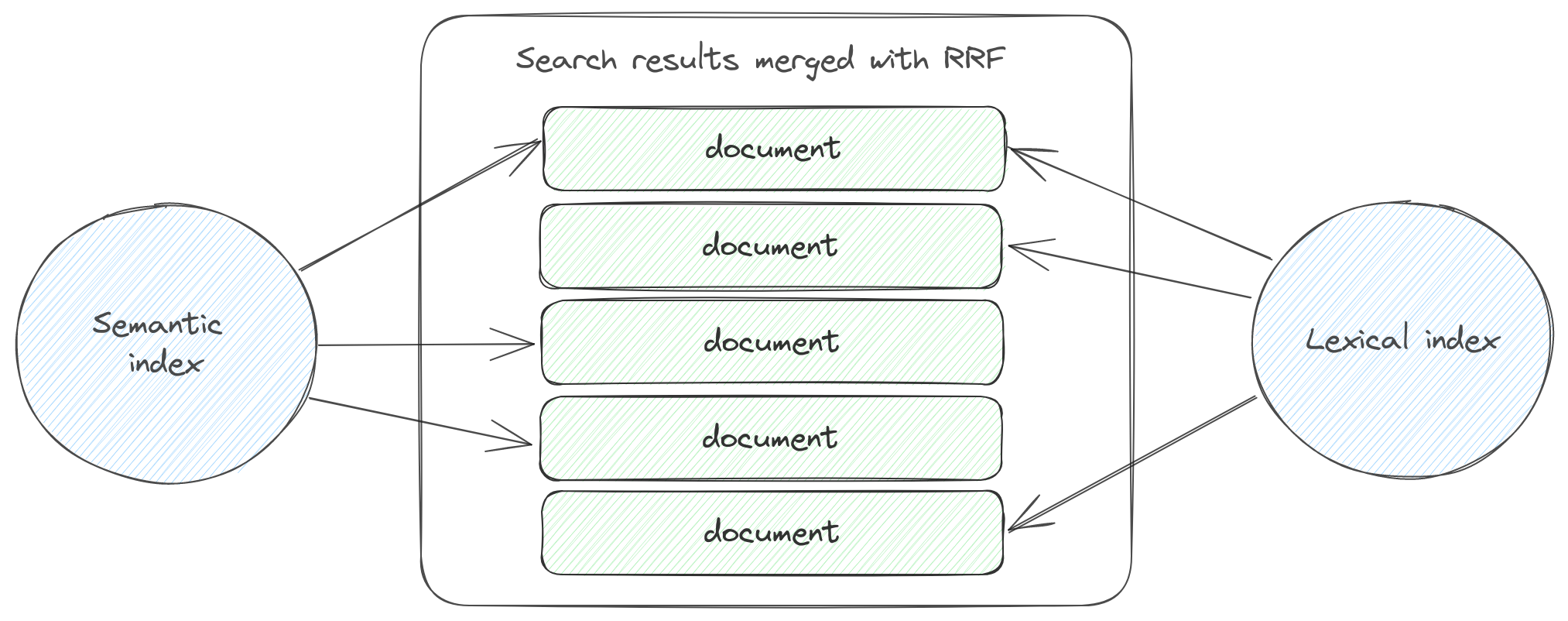
RRF merging approach:
- Does not use a document score directly (so BM25 or cosine-distance), but a document position in a result list when sorted by the score.
- Scores of documents from multiple lists are combined together.
- Final ranking is made by sorting merged document list by the combined score.
Compared to traditional methods of combining multiple BM25 and cosine scores together, RRF does not depend on the scale and statistical distribution of the underlying scores - and can generate more stable results.
Filters¶
To select a sub-set of documents for search, add filters directive to the request JSON payload:
{
"query": {
"match_all": {}
},
"filters": {
"include": {
"term": {
"field": "color",
"value": "red"
}
}
}
}
- Term filters - to match over text fields.
- Range filters - to select over numeric
int/long/float/doublefields. - Compound boolean filters - to combine multiple filter types within a single filter predicate.
See Filters DSL reference for more examples and details.
Facets¶
Facet count aggregation is useful for building a faceted search: for a search query apart from documents, response contains also a set of possible filter values (sorted by a number of documents this filter value will match).
A JSON search request payload can be extended with the aggs parameter:
{
"query": {
"multi_match": {}
},
"aggs": {
"count_colors": {
"term": {
"field": "color",
"count": 10
}
}
}
}
Where count_colors is an aggregation name, this is a term aggregation over a field color, returning top-10 most frequent values for this field.
Each facet aggregation adds an extra named section in the search response payload:
{
"hits": [
{"_id": "1", "_score": 10},
{"_id": "1", "_score": 5},
],
"aggs": {
"count_colors": {
"buckets": [
{"term": "red", "count": 10},
{"term": "green", "count": 5},
{"term": "blue", "count": 2},
]
}
}
}
See a Facet Aggregation DSL section in reference for more details.